|
I am a graduate student in the Computer Science Department at the University of Rochester. I received my B.S. in Computer Science with highest honor distinction from the University of Rochester. My research interests are multimodal large language models, visual agents, video generative models, and human-behavior understanding and generation. Email / Google Scholar / GitHub / CV |

|
|
Seeking Research / Applied Scientist / ML Engineer positions in Multimodal Language Models, Human Video Generation (3D / Diffusion), Video Understanding (MLLM), Audio-Visual Learning, and 3D Perception & Understanding. My master's research focused primarily on language models and human-centered perception/generation. |
| [02/2026] | One paper accepted to CVPR 2026. |
| [09/2025] | One co-author paper accepted Cell Reports Methods. |
| [09/2025] | One co-author paper accepted NeurIPS 2025. |
| [06/2025] | One first-author paper accepted ACM Multimedia 2025. |
| [06/2025] | Two first-author papers accepted ICCV 2025. |
| [05/2025] | Joined Meta Reality Lab as a Research Scientist Intern. |
| [11/2024] | One first-author paper accepted 3DV 2025. |
| [09/2024] | One co-author paper accepted Siggraph Asia 2024. |
| [07/2024] | One first-author paper accepted ECCV 2024. |
| [06/2024] | Joined FlawlessAI as a Research Scientist Intern. |

|
Meta, Reality Lab — Research Scientist Intern May 2025 – Dec 2025 Report to: A. Richard, D. Markovic
|

|
Flawless AI — Research Scientist Intern Jun 2024 – Dec 2024 Report to: P. Garrido, A. Shapiro
|

|
Luchuan Song*, Pinxin Liu*, Haiyang Liu, Zhenchao Jin, Yunlong Tang, Zicong Xu, Susan Liang, Jing Bi, Jason J. Corso, Chenliang Xu CVPR, 2026 project page / code / data We introduce Open3DFaceVid and cast facial-parameter modeling as a language problem, enabling bidirectional Motion2Language and Language2Motion for text-conditioned facial animation and understanding. |

|
Pinxin Liu, Pengfei Zhang, Hyeongwoo Kim, Pablo Garrido, Ari Shapiro, Kyle Olszewski ACM Multimedia, 2025 project page / paper / code We propose a context-aware gesture representation for co-speech gesture video generation. |
|
Yunlong Tang*, Jing Bi*, Siting Xu*, Luchuan Song, Susan Liang, Teng Wang, ..., Pinxin Liu, Mingqian Feng, Feng Zheng, Jianguo Zhang, Ping Luo, Jiebo Luo, Chenliang Xu IEEE Transactions on Circuits and Systems for Video Technology paper / project page A comprehensive survey on video understanding techniques powered by large language models. |
|
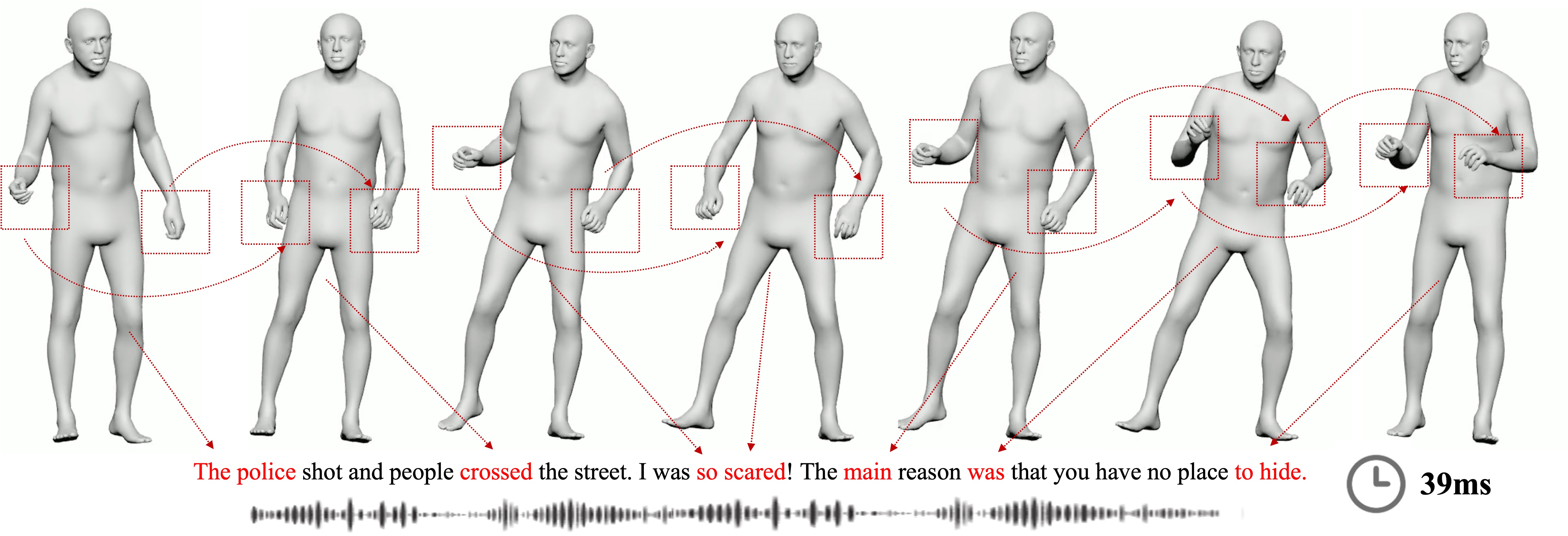
Pinxin Liu, Luchuan Song, Junhua Huang, Haiyang Liu, Chenliang Xu ICCV, 2025 project page / paper / code We propose a latent shortcut mechanism for co-speech gesture generation with spatial-temporal modeling. |

|
Pinxin Liu*, Pengfei Zhang*, Hyeongwoo Kim, Pablo Garrido, Bindita Chaudhuri ICCV, 2025 project page / paper / code We present a kinematic-aware approach for human motion understanding and generation. |
|
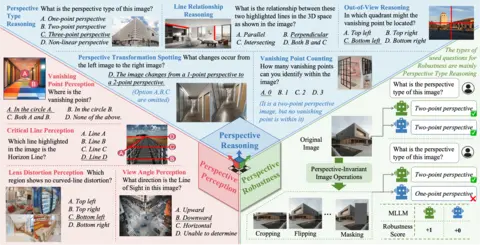
Pinxin Liu*, Yunlong Tang*, Zhangyun Tan*, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, Ali Vosoughi, Luchuan Song, Zeliang Zhang, Chenliang Xu NeurIPS, 2025 (Datasets and Benchmarks Track) project page / paper We introduce MMPerspective, the first benchmark to systematically evaluate MLLMs' understanding of perspective through 10 tasks across perception, reasoning, and robustness (2,711 images, 5,083 QA pairs). Accepted to NeurIPS 2025 DB Track. |

|
Pinxin Liu*, Luchuan Song*, Daoan Zhang, Hang Hua, Yunlong Tang, Huaijin Tu, Jiebo Luo, Chenliang Xu 3DV, 2025 paper We propose GaussianStyle, integrating 3D Gaussian Splatting with StyleGAN for head avatars. The framework preserves expression and pose with Gaussians while projecting implicit volume into StyleGAN for high-frequency detail, achieving state-of-the-art in reenactment, novel view synthesis, and animation. |
|
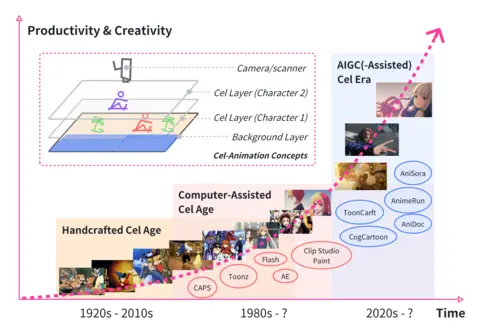
Yunlong Tang, Junjia Guo, Pinxin Liu, Zhiyuan Wang, Hang Hua, Jia-Xing Zhong, Yunzhong Xiao, Chao Huang, Luchuan Song, Susan Liang and 7 more authors ICCVW, 2025 paper / project page A comprehensive survey on generative AI for cel-animation. |

|
Luchuan Song, Lele Chen, Celong Liu, Pinxin Liu, Chenliang Xu Siggraph Asia, 2024 project page / paper / code We present a method to generate a drivable toonified avatar. Given a monocular video and a written instruction about the avatar style, it can generate a toonified avatar that can be animated in real time. |

|
Pinxin Liu*, Luchuan Song*, Lele Chen, Guojun Yin, Chenliang Xu ECCV, 2024 project page / paper / code We attach the multi-combined tri-plane structure for monocular photo-realistic volumetric head avatar reconstructions. |
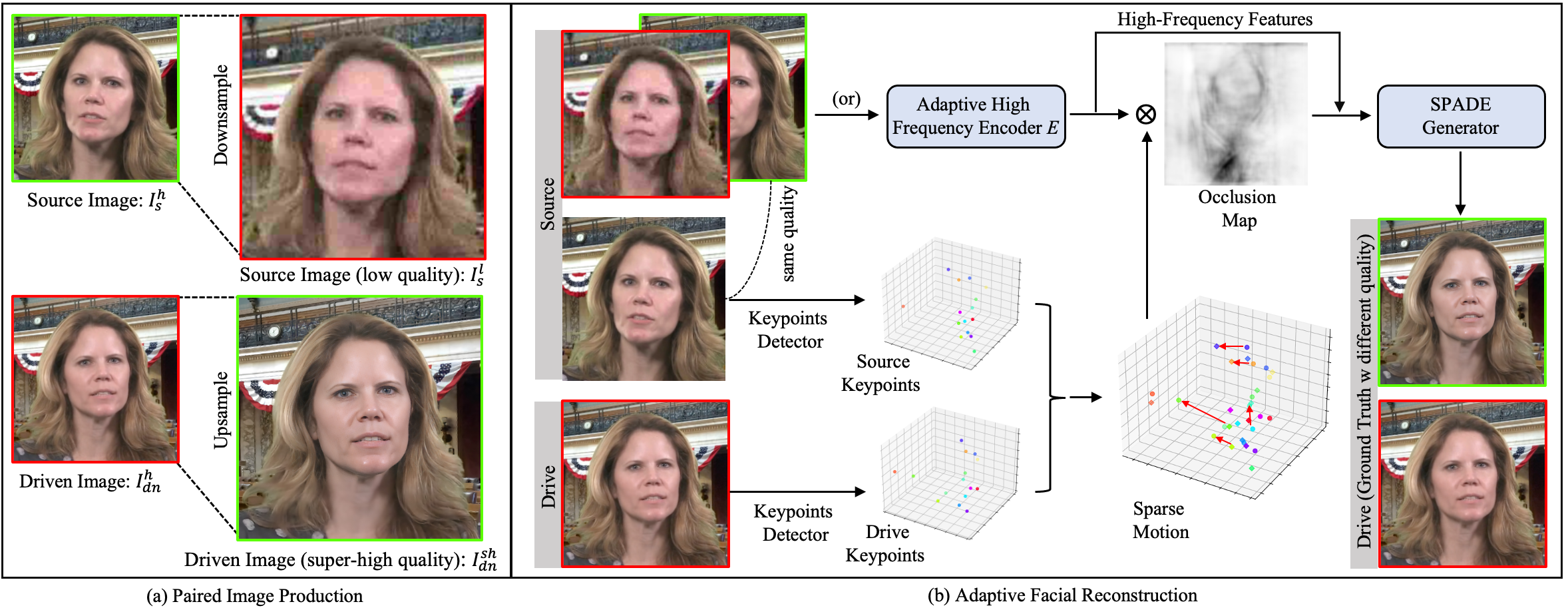
|
Luchuan Song*, Pinxin Liu*, Guojun Yin, Chenliang Xu ICASSP, 2024 paper / code / video We apply the mix-resolution images in one-shot talking head training. The resolution could achieve 512px from 256px in previous. |
| University of Rochester |
M.S., Computer Science Jan 2025 – May 2026 (expected) |
| University of Rochester |
B.S., Computer Science; Highest Honor Distinction in Research; GPA: 3.83/4.0 Jul 2020 – May 2024 |
|
|
|
|
|
|
|
|
|
|
|
Template from Jon Barron. © 2025 Pinxin Liu |